La tecnología de reconocimiento de caracteres está cada vez más integrada en el mundo empresarial, contribuyendo a automatizar tareas que anteriormente (y en muchos casos sigue siendo así) requiere personal dedicado sólo a manejar el flujo de papeles (archivar, localizar, recuperar, fotocopiar,… y vuelta a empezar).
La ventaja competitiva que supone para las empresas tener un sistema automatizado de tratamiento de documentos, con su conversión e indexación en formato PDF, siempre disponible a través de las búsquedas tanto por fechas, nombres, palabras clave, etc. hace que la adopción de estas soluciones, especialmente en los tiempos que atravesamos se convierta cada vez más en una necesidad tanto para optimizar los flujos de trabajos internos como para aprovechar al máximo el personal en tareas que realmente aporte valor añadido y eficacia a la gestión, como seguimiento de clientes, ofertas, atención y soporte al cliente, etc.
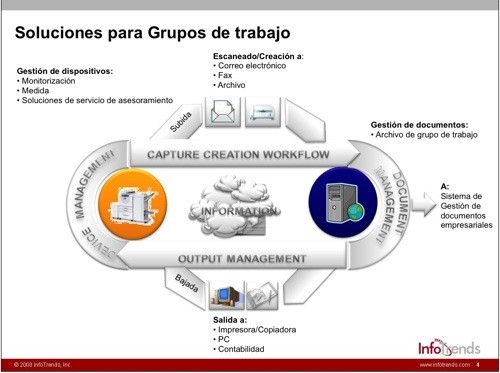
Dentro del segmento de reconocimiento óptico se reúnen ya diferentes tecnologías que son:
Índice
OCR (Optical Character Recognition) – Reconocimiento Óptico de Caracteres
En el reconocimiento óptico de caracteres se escanea una hoja escrita a máquina -como imagen- y el software reconoce los caracteres escritos y los reproduce como texto editable.
ICR (Intelligent Character Recognition) – Reconocimiento Inteligente de Caracteres
En el reconocimiento inteligente de caracteres, se escanean documentos con campos escritos a mano (como formularios, solicitudes, declaraciones de renta, etc.) y el software reconoce los caracteres manuscritos y los convierte a texto editable.
OMR (Optical Mark Recognition) – Reconocimiento de Marcas Ópticas
El reconocimiento de marcas ópticas se utiliza para reconocer casillas marcadas (como en formularios, quinielas, etc.) y “validar” el campo marcado.
Barcode – Códigos de barras
El reconocimiento de códigos de barras, como su nombre indica, requiere el escaneado de un código de barras y un software que traduzca su significado a texto plano, ya sea el código numérico, el producto que representa, etc.
Handwriting – Textos manuscritos
Escaneado de hojas manuscritas libremente y reconocimiento de los caracteres que incluyen convirtiéndolos en caracteres digitales y editables.
(Y cualquier otra cosa intermedia que puedan inventarse para vender más).
El 80 % de los documentos que manejan los empleados de una empresa están semiestructurados, es decir, tienen campos fijos que se repiten siempre, como fechas, números identificativos (números de albarán, facturas, pedidos…) nombre y dirección del remitente, del receptor, etc.
Con un documento, los procedimientos más habituales son la conversión de la página completa, clasificación en su directorio correspondiente, extracción de datos para su indexación, redacción, enrutado, autorrelleno, reutilización y rotación de imágenes.
Conversión de página completa
Supone pasar de un archivo de imagen a un archivo de datos electrónicos que incluye todo el texto de la página. Finalmente, se exportan esos datos en los formatos especificados (PDF, Doc,…)
Clasificación
La clasificación obliga al software a identificar correctamente el tipo de documento, lo que, a su vez, permite el escaneado de formatos distintos de documentos o el escaneado de documentos mezclados.
Extracción de datos para indexado
Sólo se requieren unos campos concretos, que permite normalizar los datos ya que se encuentran siempre en el mismo sitio. Su finalidad normalmente es ser exportado a una base de datos. El gran problema a superar es la fidelidad de los datos. Lógicamente, a mayor número de errores en la captura de datos mayor tiempo en repasar humanamente los mismos y menor rentabilidad del sistema.
Los tres principales actores en el segmento de reconocimiento de caracteres son:
¿Qué se necesita para comprar una solución completa de reconocimiento inteligente de caracteres?
- Dispositivo de entrada (escáner, multifuncional, archivos digitalizados,…)
- Captura (de esos datos para convertirlos a texto editable/buscable)
- Almacenamiento para guardar esos archivos (y sus copias de seguridad).
Teniendo en cuenta que los principales fabricantes son tres (como mucho cinco), a cualquier otro integrador la empresa está comprando un motor de reconocimiento de caracteres licenciado a una de estas cinco empresas fabricantes. Es crucial conocer quién respalda el motor que se va a comprar para conocer a fondo sus fortalezas y sus debilidades.
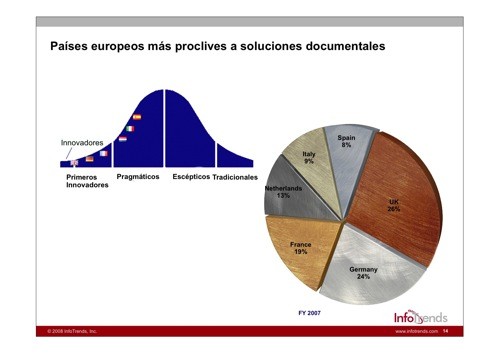
¿Cómo estamos en España en soluciones de gestión documental?
Desgraciadamente los estudios de InfoTrends colocan a España (8%) dentro de los paises “pragmáticos”, por detrás de Italia (9%) y Holanda (13%).
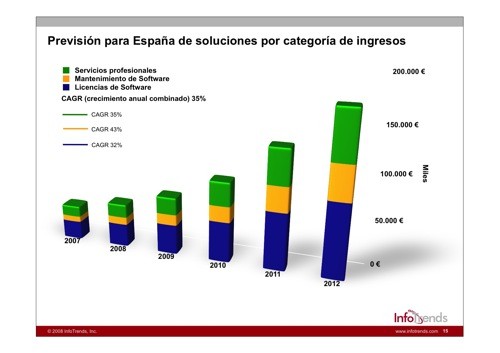
A pesar de todo, se calcula que para el año 2012 este mercado de gestión y digitalización documental supere los 150 millones de euros, en una progresión sostenida y creciente que destaca la importancia que año tras año va a cobrar para las empresas la optimización de sus flujos documentales.

La madurez y la fiabilidad de las soluciones que ya se están implantando en todo el mundo hace que su ausencia no sea justificable por razones ténicas o tecnológicas, sino a falta de voluntad (política en el caso de las administraciones) y cultural (en el caso de las empresas), puesto que soluciones de gestión “sin papeles” se están implementando con éxito rotundo por toda Europa (y lentamente parecen llegar a la administración española -especialmente a los departamentos tributarios).
Graficos cortesía de Francesco Pignatti, de InfoTrends
Este artículo forma parte de la serie “Un vistazo general del mercado de captura inteligente de caracteres” (I) y Un vistazo general del mercado de captura inteligente de caracteres” (II) y IrisLink 2009, punto de encuentro de los “sin papeles”, por Alf





Yo estoy usando hace una temporada el Acrobat para pasar el OCR, después de escanear a PDF (b/n) ó grises) desde una fotocopiadora de alta velocidad, y según el trabajo, lo uso o bien para que arregle en ángulo de las páginas el Acrobat, o para hacer búsquedas de textos. Y como no, para tener el texto como texto vectorial y pasarlo a otro programa de paginación para volver a maquetar, eso si, se ha de repasar todo, siguen confundiendo muchas veces la “ó” con el “6”, y otros errores más, al igual que si hay palabras subrayadas o con manchas suaves se confunde.